
Janne Hellsten on August 18, 2019
This post recaps some of the C64 coding tricks used in my little Commodore 64 coding competition. The competition rules were simple: make a C64 executable (PRG) that draws two lines to form the below image. The objective was to do this in as few bytes as possible.

Entries were posted as Twitter replies and DMs, containing only the PRG byte-length and an MD5 hash of the PRG file.
Here’s a list of participants with source code links to their submissions:
- Philip Heron (code – 34 bytes – compo winner)
- Geir Straume (code – 34 bytes)
- Petri Häkkinen (code – 37 bytes)
- Mathlev Raxenblatz (code – 38 bytes)
- Jan Achrenius (code – 48 bytes)
- Jamie Fuller (code – 50 bytes)
- David A. Gershman (code – 53 bytes)
- Janne Hellsten (code – 56 bytes)
(If I missed someone, please let me know and I’ll update the post.)
The rest of this post focuses on some of the assembly coding tricks used in the compo submissions.
Basics
The C64 default graphics mode is the 40×25 charset mode. The framebuffer is split into two arrays in RAM:
$0400(Screen RAM, 40×25 bytes)$d800(Color RAM, 40×25 bytes)
To set a character, you store a byte into screen RAM at $0400 (e.g., $0400+y*40+x). Color RAM is by default initialized to light blue (color 14) which happens to be the same color we use for the lines – meaning we can leave color RAM untouched.
You can control the border and background colors with memory mapped I/O registers at $d020 (border) and $d021 (background).
Drawing the two lines is pretty easy as we can hardcode for the fixed line slope. Here’s a C implementation that draws the lines and dumps screen contents on stdout (register writes stubbed out and screen RAM is malloc()’d to make it run on PC):
The screen codes used above are: $20 (blank) and $a0 (8×8 filled block). If you run it, you should see ASCII art for the two lines:
##....................................##
..#..................................#..
...##..............................##...
.....#............................#.....
......##........................##......
........##....................##........
..........#..................#..........
...........##..............##...........
.............#............#.............
..............##........##..............
................##....##................
..................#..#..................
...................##...................
..................#..#..................
................##....##................
..............##........##..............
.............#............#.............
...........##..............##...........
..........#..................#..........
........##....................##........
......##........................##......
.....#............................#.....
...##..............................##...
..#..................................#..
##....................................##Using 6502 assembly and assembly pseudos, we can trivially implement the same in assembly:
This completely unrolls the line drawing part resulting in a fairly large 286 byte PRG.
Before diving into optimized variants, let’s make a couple of observations:
First, we’re running on the C64 with the ROM routines banked in. There’s a bunch of subroutines in ROM that may be useful for our little program. For example, you can clear the screen with JSR $E544.
Second, address calculations on an 8-bit CPU like the 6502 can be cumbersome and cost a lot of bytes. This CPU also doesn’t have a multiplier, so computing something like y*40+i usually involves either a bunch of logical shifts or a lookup table, again costing bytes. To avoid multiplying by 40, we can instead advance the screen pointer incrementally:
We keep adding the line slope to a fixed point counter yf and when the 8-bit addition sets the carry flag, add 40.
Here’s the incremental approach implemented in assembly:
At 82 bytes, this is still pretty hefty. A couple of obvious size problems arise from 16-bit address computations:
Setting up the screenptr value for indirect-indexed addressing:
Advancing screenptr to the next row by adding 40:
Sure this code could probably be made smaller but what if we didn’t need manipulate 16-bit addresses in the first place? Let’s see this can be avoided.
Trick 1: Scrolling!
Instead of plotting the line across the screen RAM, we draw only on the last Y=24 screen row, and scroll the whole screen up by calling a “scroll up” ROM function with JSR $E8EA!
The x-loop becomes:
Here’s how the line renderer progresses with this trick:

This trick was one of my favorites in this compo. It was also independently discovered by pretty much every participant.
Trick 2: Self-modifying code
The code to store the pixel values ends up being roughly:
This encodes into the following 14 byte sequence:
0803: A6 22 LDX $22
0805: 9D C0 07 STA $07C0,X
0808: A6 20 LDX $20
080A: 9D C0 07 STA $07C0,X
080D: E6 22 INC $22
080F: C6 20 DEC $20There’s a more compact way to write this using self-modifying code (SMC)..
..which encodes to 13 bytes:
0803: A6 22 LDX $22
0805: 9D C0 07 STA $07C0,X
0808: 8D C0 07 STA $07C0
080B: EE 09 08 INC $0809
080E: C6 22 DEC $22Trick 3: Exploiting the power on state
Making wild assumptions about the running environment was considered OK in this compo: the line drawing PRG is the first thing that’s run after C64 power on, and there was no requirement to exit cleanly back to the BASIC prompt. So anything you find from the initial environment upon entry to your PRG, you can and should use to your advantage. Here are some of the things that were considered “constant” upon entry to the PRG:
- A, X, Y registers were assumed to be all zeros
- All CPU flags cleared
- Zeropage (addresses
$00–$ff) contents
Similarly, if you called any KERNAL ROM routines, you could totally take advantage of any side-effects they might have: returned CPU flags, temporary values set into zeropage, etc.
After the first few size-optimization passes, everyone turned their eyes on this machine monitor view to look for any interesting values:
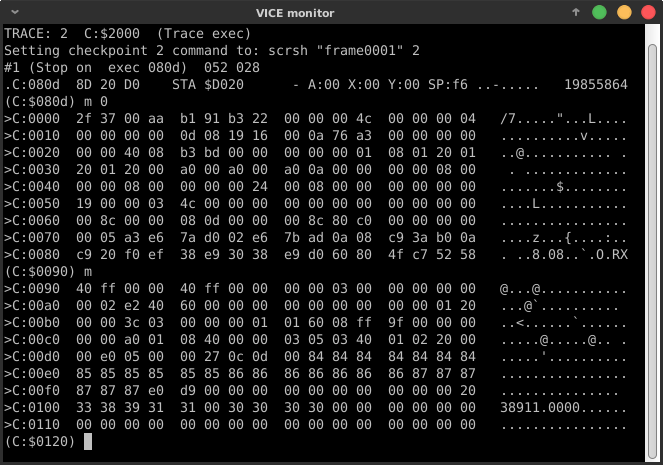
The zeropage indeed contains some useful values for our purposes:
$d5: 39/$27 == line length – 1$22: 64/$40 == initial value for line slope counter
You can use these to shave off a few bytes at init time. For example:
As $d5 contains a value 39, you can map your x0 counter to point to $d5 and skip the LDA/STA pair:
Philip’s winning entry takes this to the extreme. Recall the address of the last char row $07C0 (==$0400+24*40). This value does not exist in the zeropage on init. However, as a side-effect of how the ROM “scroll up” subroutine uses zeropage temporaries, addresses $D1-$D2 will contain $07C0 on return from this function. So instead of STA $07C0,x to store a pixel, you can use the one byte shorter indirect-indexed addressing mode store STA ($D1),y.
Trick 4: Smaller startup
A typical C64 PRG binary file contains the following:
- First 2 bytes: loading address (usually
$0801) - 12 bytes of BASIC startup sequence
The BASIC startup sequence looks like this (addresses $801-$80C):
0801: 0B 08 0A 00 9E 32 30 36 31 00 00 00
080D: 8D 20 D0 STA $D020Without going into details about tokenized BASIC memory layout, this sequence more or less amounts to “10 SYS 2061”. Address 2061 ($080D) is where our actual machine code program starts when the BASIC interpreter executes the SYS command.
14 bytes just to get going feels excessive. Philip, Mathlev and Geir had used some clever tricks to get rid of the BASIC sequence altogether. This requires that the PRG is loaded with LOAD "*",8,1 as LOAD "*",8 ignores the PRG loading address (the first two bytes) and always loads to $0801.
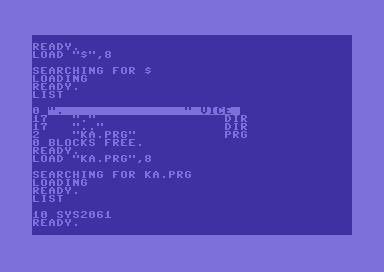
Two methods were used:
- The stack trick
- The BASIC warm reset vector trick
The stack trick
The trick is to stomp the CPU stack at $01F8 with a value that points to our desired entry point. This is done by crafting a PRG that starts with a 16-bit pointer pointing to our code and loading the PRG into $01F8:
Once the BASIC loader (see disassembly) has finished loading and returns to its caller with RTS, instead of returning to whoever called LOAD, it returns right into our PRG.
The BASIC warm reset vector trick
This is a little easier to explain by just looking at the PRG disassembly.
02E6: 20 EA E8 JSR $E8EA
02E9: A4 D5 LDY $D5
02EB: A9 A0 LDA #$A0
02ED: 99 20 D0 STA $D020,Y
02F0: 91 D1 STA ($D1),Y
02F2: 9D B5 07 STA $07B5,X
02F5: E6 D6 INC $D6
02F7: 65 90 ADC $90
02F9: 85 90 STA $90
02FB: C6 D5 DEC $D5
02FD: 30 FE BMI $02FD
02FF: 90 E7 BCC $02E8
0301: 4C E6 02 JMP $02E6Notice the last line (JMP $02E6). The JMP instruction starts at address $0301 with the branch target stored in addresses $0302-$0303.
When this code is loaded into memory starting at address $02E6, a value of $02E6 is written to addresses $0302-$0303. Well, location $0302-$0303 has a special meaning: it contains a pointer to the “BASIC idle loop” (see C64 memory map for details). Loading the PRG overwrote this location with $02E6 and so when the BASIC interpreter tries to jump to the idle loop after warm reset, it never enters the idle loop but instead ends up in the line renderer!
Petri had discovered another BASIC start trick which allows injecting your own constants into the zeropage. In this method, you hand-craft your own tokenized BASIC start sequence and encode your constants into the BASIC program line number. The BASIC line number, ahem, your constants, will be stored in addresses $39-$3A upon entry. Very clever!
Trick 5: Unconventional control flow
Here’s a somewhat simplified version of the x-loop that draws only a single line and then halts execution once the line is done:
This has a bug in it, though. When we’ve drawn the last pixel of a line, we should NOT scroll the screen up anymore. Thus we need more branching to skip scrolling on the last pixel write:
The control flow looks a lot like what a C compiler would output from a structured program. The code to skip the last scroll introduced a new JMP abs instruction that takes up 3 bytes. Conditional branches are only two bytes as they encode the branch target using a relative 8-bit immediate.
The “skip last scroll” JMP can be avoided by moving the scroll up call to the top of the loop, and restructuring the control flow a bit. This is the pattern Philip had come up with:
This completely eliminates one 3 byte JMP and converts another JMP to a 2 byte conditional branch, saving 4 bytes in total.
Trick 6: Bitpacked line drawing
Some of the entries didn’t use a line slope counter but rather they had bit-packed the line pattern into an 8-bit constant. This packing comes out of a realisation that the pixel position along the line follows a repeating 8 pixel pattern:
This translates to pretty compact assembly. The slope counter variants tended to be even smaller, though.
Winner entry
This is the winning 34 byte entry from Philip. Most of the above really comes together nicely in his code:
ov = $22 ; == $40, initial value for the overflow counter
ct = $D5 ; == $27 / 39, number of passes. Decrementing, finished at -1
lp = $D1 ; == $07C0, pointer to bottom line. Set by the kernal scroller
; Overwrite the return address of the kernal loader on the stack
; with a pointer to our own code
* = $01F8
.word scroll - 1
scroll: jsr $E8EA ; Kernal scroll up, also sets lp pointer to $07C0
loop: ldy ct ; Load the decrementing counter into Y (39 > -1)
lda #$A0 ; Load the PETSCII block / black col / ov step value
sta $D020, y ; On the last two passes, sets the background black
p1: sta $07C0 ; Draw first block (left > right line)
sta (lp), y ; Draw second block (right > left line)
inc p1 + 1 ; Increment pointer for the left > right line
adc ov ; Add step value $A0 to ov
sta ov
dec ct ; Decrement the Y counter
bmi * ; If it goes negative, we're finished
bcc loop ; Repeat. If ov didn't overflow, don't scroll
bcs scroll ; Repeat. If ov overflowed, scrollWhy stop at 34 bytes, though?
Once the competition was over, everyone shared code and notes, and a number of lively conversations took place on how to do even better. Several smaller variants were posted after the deadline:
You should check them out – there are some real gems to be found.
…
Thanks for reading. And most of all, thanks Mathlev, Phil, Geir, Petri, Jamie, Jan and David for your participation. (I hope I didn’t miss anyone – it was really difficult to keep track of these in Twitter mentions!)
PS. Petri had named my compo “@nurpax’s annual C64 size optimization compo”, so uhm, see you next year, I guess.